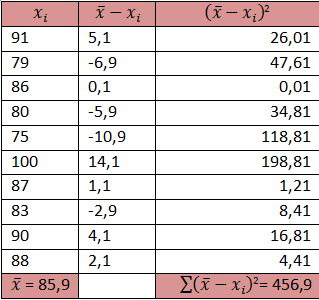
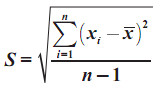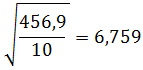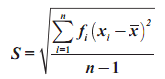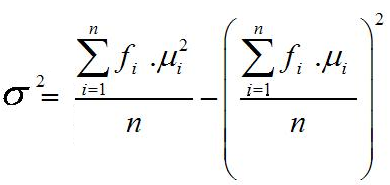Salah satu aspek yang paling penting untuk menggambarkan distribusi data adalah nilai pusat data pengamatan (
Central Tendency).
Setiap pengukuran aritmatika yang ditujukan untuk menggambarkan suatu
nilai yang mewakili nilai pusat atau nilai sentral dari suatu gugus data
(himpunan pengamatan) dikenal sebagai
ukuran pemusatan data (tendensi sentral). Terdapat tiga ukuran pemusatan data yang sering digunakan, yaitu:
- Mean (Rata-rata hitung/rata-rata aritmetika)
- Median
- Mode
Pada artikel ini akan di bahas mengenai pengertian beberapa
ukuran pemusatan data
yang dilengkapi dengan contoh perhitungan, baik untuk data tunggal
ataupun data yang sudah dikelompokkan dalam tabel distribusi frekuensi.
Selain ukuran statistik di atas, akan dibahas juga mengenai beberapa
ukuran statistik lainnya, seperti
Rata-rata Ukur (
Geometric Mean),
Rata-rata Harmonik
(H) serta beberapa karakteristik penting yang perlu dipahami untuk
ukuran tendensi sentral yang baik serta bagaimana memilih atau
menggunakan nilai tendensi sentral yang tepat.
(1) Mean (arithmetic mean)
Rata-rata hitung atau arithmetic mean atau sering disebut dengan istilah mean
saja merupakan metode yang paling banyak digunakan untuk menggambarkan
ukuran tendensi sentral. Mean dihitung dengan menjumlahkan semua nilai
data pengamatan kemudian dibagi dengan banyaknya data. Definisi
tersebut dapat di nyatakan dengan persamaan berikut:
Sampel:  Populasi:
Populasi:  Keterangan:∑ = lambang penjumlahan semua gugus data pengamatan n = banyaknya sampel data N = banyaknya data populasi
Keterangan:∑ = lambang penjumlahan semua gugus data pengamatan n = banyaknya sampel data N = banyaknya data populasi  = nilai rata-rata sampel μ = nilai rata-rata populasi Mean dilambangkan dengan (dibaca "x-bar") jika kumpulan data ini merupakan contoh (sampel) dari populasi, sedangkan jika semua data berasal dari populasi, mean dilambangkan dengan μ (huruf kecil Yunani mu).
= nilai rata-rata sampel μ = nilai rata-rata populasi Mean dilambangkan dengan (dibaca "x-bar") jika kumpulan data ini merupakan contoh (sampel) dari populasi, sedangkan jika semua data berasal dari populasi, mean dilambangkan dengan μ (huruf kecil Yunani mu).
Sampel statistik biasanya dilambangkan dengan huruf Inggris,
, sementara parameter-parameter populasi biasanya dilambangkan dengan huruf Yunani, misalnya
μ
a. Rata-rata hitung (Mean) untuk data tunggal
Contoh 1:
Hitunglah nilai rata-rata dari nilai ujian matematika kelas 3 SMU berikut ini: 2; 4; 5; 6; 6; 7; 7; 7; 8; 9
Jawab:

Nilai rata-rata dari data yang sudah dikelompokkan bisa dihitung dengan menggunakan formula berikut:
 Keterangan:
Keterangan: ∑ = lambang penjumlahan semua gugus data pengamatan f
i = frekuensi data ke-i n = banyaknya sampel data
= nilai rata-rata sampel
Contoh 2:
Berapa rata-rata hitung pada tabel frekuensi berikut:
| xi |
fi |
| 70 |
5 |
| 69 |
6 |
| 45 |
3 |
| 80 |
1 |
| 56 |
1 |
Catatan: Tabel frekuensi pada tabel di atas
merupakan tabel frekuensi untuk data tunggal, bukan tabel frekuensi dari
data yang sudah dikelompokkan berdasarkan selang/kelas tertentu.
Jawab:
| xi |
fi |
fixi |
| 70 |
5 |
350 |
| 69 |
6 |
414 |
| 45 |
3 |
135 |
| 80 |
1 |
80 |
| 56 |
1 |
56 |
| Jumlah |
16 |
1035 |


b. Mean dari data distribusi Frekuensi atau dari gabungan:
Distribusi Frekuensi:
Rata-rata hitung dari data yang sudah disusun dalam bentuk tabel
distribusi frekuensi dapat ditentukan dengan menggunakan formula yang
sama dengan formula untuk menghitung nilai rata-rata dari data yang
sudah dikelompokkan, yaitu:
 Keterangan:
Keterangan:
∑ = lambang penjumlahan semua gugus data pengamatan f
i = frekuensi data ke-i
= nilai rata-rata sampel
Contoh 3:
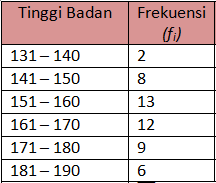
Tabel berikut ini adalah nilai ujian statistik 80 mahasiswa yang
sudah disusun dalam tabel frekuensi. Berbeda dengan contoh 2, pada
contoh ke-3 ini, tabel distribusi frekuensi dibuat dari data yang sudah
dikelompokkan berdasarkan selang/kelas tertentu (banyak kelas = 7 dan
panjang kelas = 10).
| Kelas ke- |
Nilai Ujian |
fi |
| 1 |
31 - 40 |
2 |
| 2 |
41 - 50 |
3 |
| 3 |
51 - 60 |
5 |
| 4 |
61 - 70 |
13 |
| 5 |
71 - 80 |
24 |
| 6 |
81 - 90 |
21 |
| 7 |
91 - 100 |
12 |
|
Jumlah |
80 |
Jawab:
Buat daftar tabel berikut, tentukan nilai pewakilnya (x
i) dan hitung f
ix
i.
| Kelas ke- |
Nilai Ujian |
fi |
xi |
fixi |
| 1 |
31 - 40 |
2 |
35.5 |
71.0 |
| 2 |
41 - 50 |
3 |
45.5 |
136.5 |
| 3 |
51 - 60 |
5 |
55.5 |
277.5 |
| 4 |
61 - 70 |
13 |
65.5 |
851.5 |
| 5 |
71 - 80 |
24 |
75.5 |
1812.0 |
| 6 |
81 - 90 |
21 |
85.5 |
1795.5 |
| 7 |
91 - 100 |
12 |
95.5 |
1146.0 |
|
Jumlah |
80 |
|
6090.0 |
 Catatan
Catatan: Pendekatan perhitungan nilai rata-rata
hitung dengan menggunakan distribusi frekuensi kurang akurat
dibandingkan dengan cara perhitungan rata-rata hitung dengan menggunakan
data aktualnya. Pendekatan ini seharusnya hanya digunakan apabila
tidak memungkinkan untuk menghitung nilai rata-rata hitung dari sumber
data aslinya.
Rata-rata Gabungan atau rata-rata terboboti (Weighted Mean)
Rata-rata gabungan (disebut juga
grand mean,
pooled mean, atau
rata-rata umum) adalah cara yang tepat untuk menggabungkan rata-rata hitung dari beberapa sampel.
 Contoh 4:
Contoh 4:
Tiga sub sampel masing-masing berukuran 10, 6, 8 dan rata-ratanya 145, 118, dan 162. Berapa rata-ratanya?
Jawab:
\left({\rm 145}\right){\rm +}\left({\rm 6}\right)\left({\rm 118}\right){\rm +}\left({\rm 8}\right){\rm (162)}}{{\rm 10+6+8}}=143.9")
(2) Median
Median dari
n pengukuran atau pengamatan x
1, x
2 ,..., x
n adalah nilai pengamatan yang terletak di tengah gugus data setelah data tersebut diurutkan. Apabila banyaknya pengamatan (
n) ganjil, median terletak tepat ditengah gugus data, sedangkan bila
n
genap, median diperoleh dengan cara interpolasi yaitu rata-rata dari
dua data yang berada di tengah gugus data. Dengan demikian, median
membagi himpunan pengamatan menjadi dua bagian yang sama besar, 50% dari
pengamatan terletak di bawah median dan 50% lagi terletak di atas
median. Median sering dilambangkan dengan

(dibaca "x-tilde") apabila sumber datanya berasal dari sampel

(dibaca "μ-tilde") untuk median populasi. Median tidak dipengaruhi
oleh nilai-nilai aktual dari pengamatan melainkan pada posisi mereka.
Prosedur untuk menentukan nilai median, pertama urutkan data terlebih
dahulu, kemudian ikuti salah satu prosedur berikut ini:
- Banyak data ganjil → mediannya adalah nilai yang berada tepat di tengah gugus data
- Banyak data genap → mediannya adalah rata-rata dari dua nilai data yang berada di tengah gugus data
a. Median data tunggal:
Untuk menentukan median dari data tunggal, terlebih dulu kita harus
mengetahui letak/posisi median tersebut. Posisi median dapat ditentukan
dengan menggunakan formula berikut:
}{2}")
dimana
n = banyaknya data pengamatan.
Median apabila n ganjil:
Contoh 5:
Hitunglah median dari nilai ujian matematika kelas 3 SMU berikut ini: 8; 4; 5; 6; 7; 6; 7; 7; 2; 9; 10
Jawab:
-
data: 8; 4; 5; 6; 7; 6; 7; 7; 2; 9; 10
-
setelah diurutkan: 2; 4; 5; 6; 6; 7; 7; 7; 8; 9; 10
-
banyaknya data (n) = 11
-
posisi Me = ½(11+1) = 6
-
jadi Median = 7 (data yang terletak pada urutan ke-6)
| Nilai Ujian |
2 |
4 |
5 |
6 |
6 |
7 |
7 |
7 |
8 |
9 |
10 |
| Urutan data ke- |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
|
|
|
|
|
|
↑ |
|
|
|
|
|
Median apabila n genap:
Contoh 6:
Hitunglah median dari nilai ujian matematika kelas 3 SMU berikut ini: 8; 4; 5; 6; 7; 6; 7; 7; 2; 9
Jawab:
-
data: 8; 4; 5; 6; 7; 6; 7; 7; 2; 9
-
setelah diurutkan: 2; 4; 5; 6; 6; 7; 7; 7; 8; 9
-
banyaknya data (n) = 10
-
posisi Me = ½(10+1) = 5.5
-
Data tengahnya: 6 dan 7
-
jadi Median = ½ (6+7) = 6.5 (rata-rata dari 2 data yang terletak pada urutan ke-5 dan ke-6)
| Nilai Ujian |
2 |
4 |
5 |
6 |
6 |
7 |
7 |
7 |
8 |
9 |
| Urutan data ke- |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
|
|
|
|
↑ |
|
|
|
|
b. Median dalam distribusi frekuensi:
Formula untuk menentukan median dari tabel distribusi frekuensi adalah sebagai berikut:
")
b = batas bawah kelas median dari kelas selang yang mengandung unsur atau memuat nilai median
p = panjang kelas median
n = ukuran sampel/banyak data
f = frekuensi kelas median
F = Jumlah semua frekuensi dengan tanda kelas lebih kecil dari kelas median (∑fi)
Contoh 7:
Tentukan nilai median dari tabel distribusi frekuensi pada Contoh 3 di atas!
Jawab:
| Kelas ke- |
Nilai Ujian |
fi |
fkum |
|
| 1 |
31 - 40 |
2 |
2 |
|
| 2 |
41 - 50 |
3 |
5 |
|
| 3 |
51 - 60 |
5 |
10 |
|
| 4 |
61 - 70 |
13 |
23 |
|
| 5 |
71 - 80 |
24 |
47 |
←letak kelas median |
| 6 |
81 - 90 |
21 |
68 |
|
| 7 |
91 - 100 |
12 |
80 |
|
| 8 |
Jumlah |
80 |
|
|
-
Letak kelas median: Setengah dari seluruh data = 40, terletak pada kelas ke-5 (nilai ujian 71-80)
-
b = 70.5, p = 10
-
n = 80, f = 24
-
f = 24 (frekuensi kelas median)
-
F = 2 + 3 + 5 + 13 = 23
{\rm{ = 70}}.{\rm{5 + 10}}\left( {\dfrac{{\dfrac{{\rm{1}}}{{\rm{2}}}\left( {{\rm{80}}} \right){\rm{ - 23}}}}{{{\rm{24}}}}} \right){\rm{ = 77}}.{\rm{58}}")
(3) Mode
Mode adalah data yang paling sering muncul/terjadi. Untuk
menentukan modus, pertama susun data dalam urutan meningkat atau
sebaliknya, kemudian hitung frekuensinya. Nilai yang frekuensinya
paling besar (sering muncul) adalah modus. Modus digunakan baik untuk
tipe data numerik atau pun data kategoris.
Modus tidak dipengaruhi oleh nilai ekstrem. Beberapa kemungkinan tentang modus suatu gugus data:
- Apabila pada sekumpulan data terdapat dua mode, maka gugus data tersebut dikatakan bimodal.
- Apabila pada sekumpulan data terdapat lebih dari dua mode, maka gugus data tersebut dikatakan multimodal.
- Apabila pada sekumpulan data tidak terdapat mode, maka gugus data tersebut dikatakan tidak mempunyai modus.
Meskipun suatu gugus data mungkin saja tidak memiliki modus, namun
pada suatu distribusi data kontinyu, modus dapat ditentukan secara
analitis.
- Untuk gugus data yang distribusinya simetris, nilai mean, median dan modus semuanya sama.
- Untuk distribusi miring ke kiri (negatively skewed): mean < median < modus
- untuk distribusi miring ke kanan (positively skewed): terjadi hal yang sebaliknya, yaitu mean > median > modus.

Hubungan antara ketiga ukuran tendensi sentral untuk data yang tidak
berdistribusi normal, namun hampir simetris dapat didekati dengan
menggunakan rumus empiris berikut:
Mean - Mode = 3 (Mean - Median)
a. Modus Data Tunggal:
Contoh 8:
Berapa modus dari nilai ujian matematika kelas 3 SMU berikut ini:
- 2, 4, 5, 6, 6, 7, 7, 7, 8, 9
- 2, 4, 6, 6, 6, 7, 7, 7, 8, 9
- 2, 4, 6, 6, 6, 7, 8, 8, 8, 9
- 2, 4, 5, 5, 6, 7, 7, 8, 8, 9
- 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
Jawab:
- 2, 4, 5, 6, 6, 7, 7, 7, 8, 9→ Nilai yang sering muncul adalah angka 7 (frekuensi terbanyak = 3), sehingga Modus (M) = 7
- 2, 4, 6, 6, 6, 7, 7, 7,
8, 9 → Nilai yang sering muncul adalah angka 6 dan 7 (masing-masing
muncul 3 kali), sehingga Modusnya ada dua, yaitu 6 dan 7. Gugus data
tersebut dikatakan bimodal karena mempunyai dua modus. Karena ke-2 mode
tersebut nilainya berurutan, mode sering dihitung dengan menghitung
nilai rata-rata keduanya, ½ (6+7) = 6.5.
- 2, 4, 6, 6, 6, 7, 8, 8, 8,
9 → Nilai yang sering muncul adalah angka 6 dan 8 (masing-masing muncul
3 kali), sehingga Modusnya ada dua, yaitu 6 dan 8. Gugus data tersebut
dikatakan bimodal karena mempunyai dua modus. Nilai mode tunggal tidak
dapat dihitung karena ke-2 mode tersebut tidak berurutan.
- 2, 4, 5, 5, 6, 7, 7, 8, 8,
9 → Nilai yang sering muncul adalah angka 5, 6 dan 7 (masing-masing
muncul 2 kali), sehingga Modusnya ada tiga, yaitu 5, 6 dan 7. Gugus
data tersebut dikatakan multimodal karena modusnya lebih dari dua.
-
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 → Pada gugus data tersebut, semua
frekuensi data sama, masing-masing muncul satu kali, sehingga gugus data
tersebut dikatakan tidak mempunyai modusnya
b. Mode dalam Distribusi Frekuensi:
")
dimana:
Mo = modal = kelas yang memuat modus
b = batas bawah kelas modal
p = panjang kelas modal
bmo = frekuensi dari kelas yang memuat modus (yang nilainya tertinggi)
b1= bmo – bmo-1 = frekuensi kelas modal – frekuensi kelas sebelumnya
b2 = bmo – bmo+1 = frekuensi kelas modal – frekuensi kelas sesudahnya
Contoh 9:
Tentukan nilai median dari tabel distribusi frekuensi pada Contoh 3 di atas!
Jawab:
| Kelas ke- |
Nilai Ujian |
fi |
|
| 1 |
31 - 40 |
2 |
|
| 2 |
41 - 50 |
3 |
|
| 3 |
51 - 60 |
5 |
|
| 4 |
61 - 70 |
13 |
|
|
|
|
→ b1 = (24 – 13) = 11 |
| 5 |
71 - 80 |
24 |
← kelas modal (frekuensinya paling besar) |
|
|
|
→ b2 =(24 – 21) =3 |
| 6 |
81 - 90 |
21 |
|
| 7 |
91 - 100 |
12 |
|
| 8 |
Jumlah |
80 |
|
-
Kelas modul =kelas ke-5
-
b = 71-0.5 = 70.5
-
b1 = 24 -13 = 11
-
b2 = 24 – 21 = 3
-
p = 10
{\rm =70.5+10}\left(\dfrac{{\rm 11}}{{\rm 11+3}}\right){\rm =78.36}")
Selain tiga ukuran tendensi sentral di atas (mean, median, dan mode),
terdapat ukuran tendensi sentral lainnya, yaitu rata-rata ukur (
Geometric Mean) dan rata-rata harmonis (
Harmonic Mean)
(4) Rata-rata Ukur (Geometric Mean)
Untuk gugus data positif x
1, x
2, …, x
n,
rata-rata geometrik adalah akar ke-n dari hasil perkalian unsur-unsur
datanya. Secara matematis dapat dinyatakan dengan formula berikut:
![U = \sqrt[n]{{{x_1}.{x_2}.{x_3} \ldots .{x_n}}}\;{\rm{atau}}\;U = \sqrt[n]{{\prod\limits_{i = 1}^n {{x_i}} }}\;{\rm{atau}}\;{\rm{Log}}(U) = \dfrac{{\Sigma \log ({x_i})\;}}{n}](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_sFA5tRD7VoXQbopWV6kyutjawwI7ql5qB6kuEF5_HEn98jALAnkEvmQBTcE3kpflME-ANS0N5k_faDlzv7dlmvefOpDINNC_de82Q9JgkmtbJdnbQuJUMcJya-AwIcq9bdbICxAlGZDprdscyi5RiaTOWOxW4AXou1iNOW1ctUiFCtVTijEYlcV7sM9cknJTQGke7rKvM7fmGGY1J7irNS8gG4q0vRpX-7OVLlFPpcDTr2m7BdycH23QQoPbtzjI233WZOEA14zfd2-3xqZRjJ10AryZfOPvrXYnMLscx8XqLSqVtcFAPcsyfSADmEi70-WO-8qkHES58DEfh-YzYb066Z00WX2rkReA7sQQbkD64U2b4KByeBa7evAOZMkZHMjbSM5MC7ORVkAAOMVtCN2Hf_yTmHjRoTcIMTHIog5NroazkAEnMsynZ-KxRDG7l7esTzJ-PdFUJIhsLS42BBRBEsKAROnFxQUxLaNc_E7uy7ibsDnBhDMl7Spg0=s0-d "U = \sqrt[n]{{{x_1}.{x_2}.{x_3} \ldots .{x_n}}}\;{\rm{atau}}\;U = \sqrt[n]{{\prod\limits_{i = 1}^n {{x_i}} }}\;{\rm{atau}}\;{\rm{Log}}(U) = \dfrac{{\Sigma \log ({x_i})\;}}{n}")
Dimana: U = rata-rata ukur (rata-rata geometrik) n = banyaknya
sampel Π = Huruf kapital π (pi) yang menyatakan jumlah dari hasil kali
unsur-unsur data. Rata-rata geometrik sering digunakan dalam bisnis dan
ekonomi untuk menghitung rata-rata tingkat perubahan, rata-rata tingkat
pertumbuhan, atau rasio rata-rata untuk data berurutan tetap atau
hampir tetap atau untuk rata-rata kenaikan dalam bentuk persentase.
a. Rata-rata ukur untuk data tunggal
Contoh 10:
Berapakah rata-rata ukur dari data 2, 4, 8?
Jawab:
![U=\sqrt[3]{\left(2\right)\left(4\right)(8)}=\sqrt[3]{64}=4](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_vZvWCWu6bzP83Rz3Ou331T_xKwmnRmLuRGDeoMey83wqHdbB3YSlAHzJicM6vyiqsXIOSsPYBwYJqVVG0UcsRqJ-I8_dQow3ZlAsrIorqBvlo5LX6gfk9BF02h-rAmxv4qDstIcf-bi4LV0pWFHWWSU0QobpbAXe5uGmWldN--hMX3bNi5B05UjrKKha4efWMdksOTqzupnn4Q36n1RKrE7owQtfQ=s0-d "U=\sqrt[3]{\left(2\right)\left(4\right)(8)}=\sqrt[3]{64}=4")
atau:
 = \dfrac{{\Sigma \log ({x_i})\;}}{n}")
 = \dfrac{{\log \left( 2 \right)\; + \log \left( 4 \right)\; + \log \left( 8 \right)\;}}{3} = \dfrac{{0.3010 + 0.6021 + 0.9031}}{3} = 0.6021")

b. Distribusi Frekuensi:
 = \dfrac{{\Sigma ({f_i}.\log \left( {{x_i})} \right)\;}}{{\Sigma {f_i}}}")
xi = tanda kelas (nilai tengah)
fi = frekuensi yang sesuai dengan xi
Contoh 11:
Tentukan rata-rata ukur dari tabel distribusi frekuensi pada Contoh 3 di atas!
Jawab
| Kelas ke- |
Nilai Ujian |
fi |
xi |
log xi |
fi.log xi |
| 1 |
31 - 40 |
2 |
35.5 |
1.5502 |
3.1005 |
| 2 |
41 - 50 |
3 |
45.5 |
1.6580 |
4.9740 |
| 3 |
51 - 60 |
5 |
55.5 |
1.7443 |
8.7215 |
| 4 |
61 - 70 |
13 |
65.5 |
1.8162 |
23.6111 |
| 5 |
71 - 80 |
24 |
75.5 |
1.8779 |
45.0707 |
| 6 |
81 - 90 |
21 |
85.5 |
1.9320 |
40.5713 |
| 7 |
91 - 100 |
12 |
95.5 |
1.9800 |
23.7600 |
| 8 |
Jumlah |
80 |
|
|
149.8091 |
=\dfrac{\Sigma {{{\rm f}}_{{\rm i}}{\rm .log} \left(x_i\right)\ }}{\Sigma {{\rm f}}_{{\rm i}}}=\dfrac{149.8091}{80}=1.8726{\rm : U}={10}^{1.8726}=74.5786")
(5) Rata-rata Harmonik (H)
Rata-rata harmonik dari suatu kumpulan data x
1, x
2, …, x
n adalah kebalikan dari nilai rata-rata hitung (aritmetik mean). Secara matematis dapat dinyatakan dengan formula berikut:
}}")
Secara umum, rata-rata harmonic jarang digunakan. Rata-rata ini
hanya digunakan untuk data yang bersifat khusus. Misalnya,rata-rata
harmonik sering digunakan sebagai ukuran tendensi sentral untuk kumpulan
data yang menunjukkan adanya laju perubahan, seperti kecepatan.
a. Rata-rata harmonic untuk data tunggal
Contoh 12:
Si A bepergian pulang pergi. Waktu pergi ia mengendarai kendaraan
dengan kecepatan 10 km/jam, sedangkan waktu kembalinya 20 km/jam.
Berapakah rata-rata kecepatan pulang pergi?
Jawab:
Apabila kita menghitungnya dengan menggunakan rumus jarak dan
kecepatan, tentu hasilnya 13.5 km/jam! Apabila kita gunakan perhitungan
rata-rata hitung, hasilnya tidak tepat!
}{2}=15\ {\rm km/jam}")
Pada kasus ini, lebih tepat menggunakan rata-rata harmonik:

b. Rata-rata Harmonik untuk Distribusi Frekuensi:
}}") Contoh 13:
Contoh 13:
Berapa rata-rata Harmonik dari tabel distribusi frekuensi pada Contoh 3 di atas!
Jawab:
| Kelas ke- |
Nilai Ujian |
fi |
xi |
fi/xi |
| 1 |
31 - 40 |
2 |
35.5 |
0.0563 |
| 2 |
41 - 50 |
3 |
45.5 |
0.0659 |
| 3 |
51 - 60 |
5 |
55.5 |
0.0901 |
| 4 |
61 - 70 |
13 |
65.5 |
0.1985 |
| 5 |
71 - 80 |
24 |
75.5 |
0.3179 |
| 6 |
81 - 90 |
21 |
85.5 |
0.2456 |
| 7 |
91 - 100 |
12 |
95.5 |
0.1257 |
| 8 |
Jumlah |
80 |
|
1.1000 |
}}=\dfrac{80}{1.10000}=72.7283")
Perbandingan Ketiga Rata-rata (Mean):


Karakteristik penting untuk ukuran tendensi sentral yang baik
Ukuran nilai pusat/tendensi sentral (
average) merupakan nilai pewakil dari suatu distribusi data, sehingga harus memiliki sifat-sifat berikut:
- Harus mempertimbangkan semua gugus data
- Tidak boleh terpengaruh oleh nilai-nilai ekstrim.
- Harus stabil dari sampel ke sampel.
- Harus mampu digunakan untuk analisis statistik lebih lanjut.
Dari beberapa ukuran nilai pusat, Mean hampir memenuhi semua
persyaratan tersebut, kecuali syarat pada point kedua, rata-rata
dipengaruhi oleh nilai ekstrem. Sebagai contoh, jika item adalah 2; 4;
5; 6; 6; 6; 7; 7; 8; 9 maka mean, median dan modus semua bernilai sama,
yaitu 6. Jika nilai terakhir adalah 90 bukan 9, rata-rata akan menjadi
14.10, sedangkan median dan modus tidak berubah. Meskipun dalam hal ini
median dan modus lebih baik, namun tidak memenuhi persyaratan lainnya.
Oleh karena itu Mean merupakan ukuran nilai pusat yang terbaik dan
sering digunakan dalam analisis statistik.
Kapan kita menggunakan nilai tendensi sentral yang berbeda?
Nilai ukuran pusat yang tepat untuk digunakan tergantung pada sifat
data, sifat distribusi frekuensi dan tujuan. Jika data bersifat
kualitatif, hanya modus yang dapat digunakan. Sebagai contoh, apabila
kita tertarik untuk mengetahui jenis tanah yang khas di suatu lokasi,
atau pola tanam di suatu daerah, kita hanya dapat menggunakan modus. Di
sisi lain, jika data bersifat kuantitatif, kita dapat menggunakan salah
satu dari ukuran nilai pusat tersebut, mean atau median atau modus.
Meskipun pada jenis data kuantitatif kita dapat menggunakan ketiga
ukuran tendensi sentral, namun kita harus mempertimbangkan sifat
distribusi frekuensi dari gugus data tersebut.
- Bila distribusi frekuensi data tidak normal (tidak simetris), median atau modus merupakan ukuran pusat yang tepat.
- Apabila terdapat nilai-nilai ekstrim, baik kecil atau besar, lebih tepat menggunakan median atau modus.
- Apabila distribusi data normal (simetris), semua ukuran nilai pusat, baik mean, median, atau modus dapat digunakan. Namun, mean lebih sering digunakan dibanding yang lainnya karena lebih memenuhi persyaratan untuk ukuran pusat yang baik.
- Ketika kita berhadapan dengan laju, kecepatan dan harga lebih tepat menggunakan rata-rata harmonik.
- Jika kita tertarik pada perubahan relatif, seperti dalam kasus pertumbuhan bakteri, pembelahan sel dan sebagainya, rata-rata geometrik adalah rata-rata yang paling tepat.